diff --git a/src/basic/compound-type/array.md b/src/basic/compound-type/array.md
index 16e57fbd..b334a1ea 100644
--- a/src/basic/compound-type/array.md
+++ b/src/basic/compound-type/array.md
@@ -113,7 +113,7 @@ note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
#### 数组元素为非基础类型
-学习了上面的知识,很多朋友肯定觉得已经学会了Rust的数组类型,但现实会给我们一记重锤,实际开发中还会碰到一种情况,就是**数组元素是非基本类型**的,这时候大家一定会这样写。
+学习了上面的知识,很多朋友肯定觉得已经学会了 Rust 的数组类型,但现实会给我们一记重锤,实际开发中还会碰到一种情况,就是**数组元素是非基本类型**的,这时候大家一定会这样写。
```rust
let array = [String::from("rust is good!"); 8];
@@ -133,7 +133,7 @@ error[E0277]: the trait bound `String: std::marker::Copy` is not satisfied
= note: the `Copy` trait is required because this value will be copied for each element of the array
```
-有些还没有看过特征的小伙伴,有可能不太明白这个报错,不过这个目前可以不提,我们就拿之前所学的[所有权](https://course.rs/basic/ownership/ownership.html)知识,就可以思考明白,前面几个例子都是Rust的基本类型,而**基本类型在Rust中赋值是以Copy的形式**,这时候你就懂了吧,`let array=[3;5]`底层就是不断的Copy出来的,但很可惜复杂类型都没有深拷贝,只能一个个创建。
+有些还没有看过特征的小伙伴,有可能不太明白这个报错,不过这个目前可以不提,我们就拿之前所学的[所有权](https://course.rs/basic/ownership/ownership.html)知识,就可以思考明白,前面几个例子都是 Rust 的基本类型,而**基本类型在 Rust 中赋值是以 Copy 的形式**,这时候你就懂了吧,`let array=[3;5]`底层就是不断的Copy出来的,但很可惜复杂类型都没有深拷贝,只能一个个创建。
接着就有小伙伴会这样写。
@@ -169,7 +169,7 @@ assert_eq!(slice, &[2, 3]);
- 切片的长度可以与数组不同,并不是固定的,而是取决于你使用时指定的起始和结束位置
- 创建切片的代价非常小,因为切片只是针对底层数组的一个引用
-- 切片类型[T]拥有不固定的大小,而切片引用类型&[T]则具有固定的大小,因为 Rust 很多时候都需要固定大小数据类型,因此&[T]更有用,`&str`字符串切片也同理
+- 切片类型 [T] 拥有不固定的大小,而切片引用类型 &[T] 则具有固定的大小,因为 Rust 很多时候都需要固定大小数据类型,因此 &[T] 更有用,`&str` 字符串切片也同理
## 总结
@@ -208,7 +208,7 @@ fn main() {
做个总结,数组虽然很简单,但是其实还是存在几个要注意的点:
-- **数组类型容易跟数组切片混淆**,[T;n]描述了一个数组的类型,而[T]描述了切片的类型, 因为切片是运行期的数据结构,它的长度无法在编译期得知,因此不能用[T;n]的形式去描述
+- **数组类型容易跟数组切片混淆**,[T;n] 描述了一个数组的类型,而 [T] 描述了切片的类型, 因为切片是运行期的数据结构,它的长度无法在编译期得知,因此不能用 [T;n] 的形式去描述
- `[u8; 3]`和`[u8; 4]`是不同的类型,数组的长度也是类型的一部分
- **在实际开发中,使用最多的是数组切片[T]**,我们往往通过引用的方式去使用`&[T]`,因为后者有固定的类型大小
diff --git a/src/basic/compound-type/enum.md b/src/basic/compound-type/enum.md
index f8b61660..7f480333 100644
--- a/src/basic/compound-type/enum.md
+++ b/src/basic/compound-type/enum.md
@@ -18,7 +18,7 @@ enum PokerSuit {
任何一张扑克,它的花色肯定会落在四种花色中,而且也只会落在其中一个花色上,这种特性非常适合枚举的使用,因为**枚举值**只可能是其中某一个成员。抽象来看,四种花色尽管是不同的花色,但是它们都是扑克花色这个概念,因此当某个函数处理扑克花色时,可以把它们当作相同的类型进行传参。
细心的读者应该注意到,我们对之前的 `枚举类型` 和 `枚举值` 进行了重点标注,这是因为对于新人来说容易混淆相应的概念,总而言之:
-**枚举类型是一个类型,它会包含所有可能的枚举成员, 而枚举值是该类型中的具体某个成员的实例。**
+**枚举类型是一个类型,它会包含所有可能的枚举成员,而枚举值是该类型中的具体某个成员的实例。**
## 枚举值
@@ -134,7 +134,7 @@ enum IpAddr {
这个例子跟我们之前的扑克牌很像,只不过枚举成员包含的类型更复杂了,变成了结构体:分别通过 `Ipv4Addr` 和 `Ipv6Addr` 来定义两种不同的 IP 数据。
-从这些例子可以看出,**任何类型的数据都可以放入枚举成员中**: 例如字符串、数值、结构体甚至另一个枚举。
+从这些例子可以看出,**任何类型的数据都可以放入枚举成员中**:例如字符串、数值、结构体甚至另一个枚举。
增加一些挑战?先看以下代码:
@@ -207,7 +207,7 @@ enum Websocket {
## Option 枚举用于处理空值
-在其它编程语言中,往往都有一个 `null` 关键字,该关键字用于表明一个变量当前的值为空(不是零值,例如整型的零值是 0),也就是不存在值。当你对这些 `null` 进行操作时,例如调用一个方法,就会直接抛出**null 异常**,导致程序的崩溃,因此我们在编程时需要格外的小心去处理这些 `null` 空值。
+在其它编程语言中,往往都有一个 `null` 关键字,该关键字用于表明一个变量当前的值为空(不是零值,例如整型的零值是 0),也就是不存在值。当你对这些 `null` 进行操作时,例如调用一个方法,就会直接抛出 **null 异常**,导致程序的崩溃,因此我们在编程时需要格外的小心去处理这些 `null` 空值。
> Tony Hoare, `null` 的发明者,曾经说过一段非常有名的话:
>
diff --git a/src/basic/compound-type/intro.md b/src/basic/compound-type/intro.md
index 77dcd2bb..0c94879d 100644
--- a/src/basic/compound-type/intro.md
+++ b/src/basic/compound-type/intro.md
@@ -30,7 +30,7 @@ fn main() {
}
```
-接下来我们的学习非常类似原型设计:有的方法只提供 API 接口,但是不提供具体实现。此外,有的变量在声明之后并未使用,因此在这个阶段我们需要排除一些编译器噪音(Rust 在编译的时候会扫描代码,变量声明后未使用会以 `warning` 警告的形式进行提示),引入 `#![allow(unused_variables)]` 属性标记,该标记会告诉编译器忽略未使用的变量,不要抛出 `warning` 警告,具体的常见编译器属性你可以在这里查阅:[编译器属性标记](https://course.rs/profiling/compiler/attributes.html)。
+接下来我们的学习非常类似原型设计:有的方法只提供 API 接口,但是不提供具体实现。此外,有的变量在声明之后并未使用,因此在这个阶段我们需要排除一些编译器噪音(Rust 在编译的时候会扫描代码,变量声明后未使用会以 `warning` 警告的形式进行提示),引入 `#![allow(unused_variables)]` 属性标记,该标记会告诉编译器忽略未使用的变量,不要抛出 `warning` 警告,具体的常见编译器属性你可以在这里查阅:[编译器属性标记](https://course.rs/profiling/compiler/attributes.html)。
`read` 函数也非常有趣,它返回一个 `!` 类型,这个表明该函数是一个发散函数,不会返回任何值,包括 `()`。`unimplemented!()` 告诉编译器该函数尚未实现,`unimplemented!()` 标记通常意味着我们期望快速完成主要代码,回头再通过搜索这些标记来完成次要代码,类似的标记还有 `todo!()`,当代码执行到这种未实现的地方时,程序会直接报错。你可以反注释 `read(&mut f1, &mut vec![]);` 这行,然后再观察下结果。
diff --git a/src/basic/compound-type/string-slice.md b/src/basic/compound-type/string-slice.md
index 85b55d46..85cb6c6a 100644
--- a/src/basic/compound-type/string-slice.md
+++ b/src/basic/compound-type/string-slice.md
@@ -95,9 +95,9 @@ let slice = &s[..];
> ```
>
> 因为我们只取 `s` 字符串的前两个字节,但是本例中每个汉字占用三个字节,因此没有落在边界处,也就是连 `中` 字都取不完整,此时程序会直接崩溃退出,如果改成 `&s[0..3]`,则可以正常通过编译。
-> 因此,当你需要对字符串做切片索引操作时,需要格外小心这一点, 关于该如何操作 UTF-8 字符串,参见[这里](#操作-utf-8-字符串)。
+> 因此,当你需要对字符串做切片索引操作时,需要格外小心这一点,关于该如何操作 UTF-8 字符串,参见[这里](#操作-utf-8-字符串)。
-字符串切片的类型标识是 `&str`,因此我们可以这样声明一个函数,输入 `String` 类型,返回它的切片: `fn first_word(s: &String) -> &str `。
+字符串切片的类型标识是 `&str`,因此我们可以这样声明一个函数,输入 `String` 类型,返回它的切片:`fn first_word(s: &String) -> &str `。
有了切片就可以写出这样的代码:
@@ -152,7 +152,7 @@ assert_eq!(slice, &[2, 3]);
## 字符串字面量是切片
-之前提到过字符串字面量,但是没有提到它的类型:
+之前提到过字符串字面量,但是没有提到它的类型:
```rust
let s = "Hello, world!";
@@ -705,9 +705,9 @@ for b in "中国人".bytes() {
// s 不再有效,内存被释放
```
-与其它系统编程语言的 `free` 函数相同,Rust 也提供了一个释放内存的函数: `drop`,但是不同的是,其它语言要手动调用 `free` 来释放每一个变量占用的内存,而 Rust 则在变量离开作用域时,自动调用 `drop` 函数: 上面代码中,Rust 在结尾的 `}` 处自动调用 `drop`。
+与其它系统编程语言的 `free` 函数相同,Rust 也提供了一个释放内存的函数: `drop`,但是不同的是,其它语言要手动调用 `free` 来释放每一个变量占用的内存,而 Rust 则在变量离开作用域时,自动调用 `drop` 函数:上面代码中,Rust 在结尾的 `}` 处自动调用 `drop`。
-> 其实,在 C++ 中,也有这种概念: _Resource Acquisition Is Initialization (RAII)_。如果你使用过 RAII 模式的话应该对 Rust 的 `drop` 函数并不陌生。
+> 其实,在 C++ 中,也有这种概念:_Resource Acquisition Is Initialization (RAII)_。如果你使用过 RAII 模式的话应该对 Rust 的 `drop` 函数并不陌生。
这个模式对编写 Rust 代码的方式有着深远的影响,在后面章节我们会进行更深入的介绍。
diff --git a/src/basic/compound-type/struct.md b/src/basic/compound-type/struct.md
index 15c41821..698a5229 100644
--- a/src/basic/compound-type/struct.md
+++ b/src/basic/compound-type/struct.md
@@ -125,7 +125,7 @@ fn build_user(email: String, username: String) -> User {
> 聪明的读者肯定要发问了:明明有三个字段进行了自动赋值,为何只有 `username` 发生了所有权转移?
>
> 仔细回想一下[所有权](https://course.rs/basic/ownership/ownership.html#拷贝浅拷贝)那一节的内容,我们提到了 `Copy` 特征:实现了 `Copy` 特征的类型无需所有权转移,可以直接在赋值时进行
-> 数据拷贝,其中 `bool` 和 `u64` 类型就实现了 `Copy` 特征,因此 `active` 和 `sign_in_count` 字段在赋值给 `user2` 时,仅仅发生了拷贝,而不是所有权转移。
+>数据拷贝,其中 `bool` 和 `u64` 类型就实现了 `Copy` 特征,因此 `active` 和 `sign_in_count` 字段在赋值给 `user2` 时,仅仅发生了拷贝,而不是所有权转移。
>
> 值得注意的是:`username` 所有权被转移给了 `user2`,导致了 `user1` 无法再被使用,但是并不代表 `user1` 内部的其它字段不能被继续使用,例如:
@@ -184,7 +184,7 @@ println!("{:?}", user1);
上面定义的 `File` 结构体在内存中的排列如下图所示:
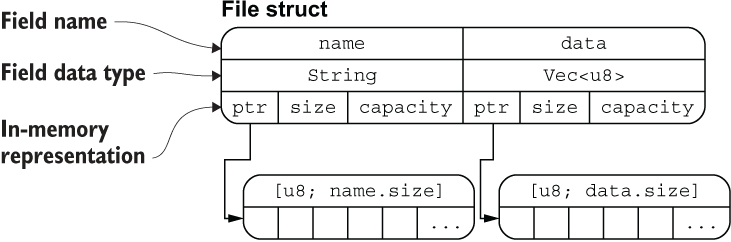 -从图中可以清晰地看出 `File` 结构体两个字段 `name` 和 `data` 分别拥有底层两个 `[u8]` 数组的所有权(`String` 类型的底层也是 `[u8]` 数组),通过 `ptr` 指针指向底层数组的内存地址,这里你可以把 `ptr` 指针理解为 Rust 中的引用类型。
+从图中可以清晰地看出 `File` 结构体两个字段 `name` 和 `data` 分别拥有底层两个 `[u8]` 数组的所有权(`String` 类型的底层也是 `[u8]` 数组),通过 `ptr` 指针指向底层数组的内存地址,这里你可以把 `ptr` 指针理解为 Rust 中的引用类型。
该图片也侧面印证了:**把结构体中具有所有权的字段转移出去后,将无法再访问该字段,但是可以正常访问其它的字段**。
@@ -206,7 +206,7 @@ println!("{:?}", user1);
还记得之前讲过的基本没啥用的[单元类型](https://course.rs/basic/base-type/char-bool.html#单元类型)吧?单元结构体就跟它很像,没有任何字段和属性,但是好在,它还挺有用。
-如果你定义一个类型,但是不关心该类型的内容, 只关心它的行为时,就可以使用 `单元结构体`:
+如果你定义一个类型,但是不关心该类型的内容,只关心它的行为时,就可以使用 `单元结构体`:
```rust
struct AlwaysEqual;
diff --git a/src/basic/flow-control.md b/src/basic/flow-control.md
index 2f2eef1b..8309a2ac 100644
--- a/src/basic/flow-control.md
+++ b/src/basic/flow-control.md
@@ -8,7 +8,7 @@
> if else 无处不在 -- 鲁迅
-但凡你能找到一门编程语言没有 `if else`,那么一定更要反馈给鲁迅,反正不是我说的:) 总之,只要你拥有其它语言的编程经验,就一定会有以下认知:`if else` **表达式**根据条件执行不同的代码分支:
+但凡你能找到一门编程语言没有 `if else`,那么一定更要反馈给鲁迅,反正不是我说的 :) 总之,只要你拥有其它语言的编程经验,就一定会有以下认知:`if else` **表达式**根据条件执行不同的代码分支:
```rust
if condition == true {
@@ -38,7 +38,7 @@ fn main() {
以上代码有以下几点要注意:
- **`if` 语句块是表达式**,这里我们使用 `if` 表达式的返回值来给 `number` 进行赋值:`number` 的值是 `5`
-- 用 `if` 来赋值时,要保证每个分支返回的类型一样(事实上,这种说法不完全准确,见[这里](https://course.rs/appendix/expressions.html#if表达式)),此处返回的 `5` 和 `6` 就是同一个类型,如果返回类型不一致就会报错
+- 用 `if` 来赋值时,要保证每个分支返回的类型一样(事实上,这种说法不完全准确,见[这里](https://course.rs/appendix/expressions.html#if表达式)),此处返回的 `5` 和 `6` 就是同一个类型,如果返回类型不一致就会报错
```console
error[E0308]: if and else have incompatible types
@@ -118,7 +118,7 @@ for item in &container {
}
```
-> 对于实现了 `copy` 特征的数组(例如 [i32; 10] )而言, `for item in arr` 并不会把 `arr` 的所有权转移,而是直接对其进行了拷贝,因此循环之后仍然可以使用 `arr` 。
+> 对于实现了 `copy` 特征的数组(例如 [i32; 10])而言, `for item in arr` 并不会把 `arr` 的所有权转移,而是直接对其进行了拷贝,因此循环之后仍然可以使用 `arr` 。
如果想在循环中,**修改该元素**,可以使用 `mut` 关键字:
diff --git a/src/basic/match-pattern/match-if-let.md b/src/basic/match-pattern/match-if-let.md
index 8b38ec0b..1c13d13c 100644
--- a/src/basic/match-pattern/match-if-let.md
+++ b/src/basic/match-pattern/match-if-let.md
@@ -144,7 +144,7 @@ fn value_in_cents(coin: Coin) -> u8 {
上面代码中,在匹配 `Coin::Quarter(state)` 模式时,我们把它内部存储的值绑定到了 `state` 变量上,因此 `state` 变量就是对应的 `UsState` 枚举类型。
-例如有一个印了阿拉斯加州标记的 25 分硬币:`Coin::Quarter(UsState::Alaska)`, 它在匹配时,`state` 变量将被绑定 `UsState::Alaska` 的枚举值。
+例如有一个印了阿拉斯加州标记的 25 分硬币:`Coin::Quarter(UsState::Alaska)`,它在匹配时,`state` 变量将被绑定 `UsState::Alaska` 的枚举值。
再来看一个更复杂的例子:
@@ -236,7 +236,7 @@ error[E0004]: non-exhaustive patterns: `West` not covered // 非穷尽匹配,`
= note: the matched value is of type `Direction`
```
-不禁想感叹,Rust 的编译器**真强大**,忍不住想爆粗口了,sorry,如果你以后进一步深入使用 Rust 也会像我这样感叹的。Rust 编译器清晰地知道 `match` 中有哪些分支没有被覆盖, 这种行为能强制我们处理所有的可能性,有效避免传说中价值**十亿美金**的 `null` 陷阱。
+不禁想感叹,Rust 的编译器**真强大**,忍不住想爆粗口了,sorry,如果你以后进一步深入使用 Rust 也会像我这样感叹的。Rust 编译器清晰地知道 `match` 中有哪些分支没有被覆盖,这种行为能强制我们处理所有的可能性,有效避免传说中价值**十亿美金**的 `null` 陷阱。
#### `_` 通配符
@@ -342,7 +342,7 @@ assert!(matches!(bar, Some(x) if x > 2));
## 变量遮蔽
-无论是 `match` 还是 `if let`,这里都是一个新的代码块,而且这里的绑定相当于新变量,如果你使用同名变量,会发生变量遮蔽:
+无论是 `match` 还是 `if let`,这里都是一个新的代码块,而且这里的绑定相当于新变量,如果你使用同名变量,会发生变量遮蔽:
```rust
fn main() {
diff --git a/src/basic/match-pattern/option.md b/src/basic/match-pattern/option.md
index 634a46db..12714b98 100644
--- a/src/basic/match-pattern/option.md
+++ b/src/basic/match-pattern/option.md
@@ -32,7 +32,7 @@ let six = plus_one(five);
let none = plus_one(None);
```
-`plus_one` 接受一个 `Option` 类型的参数,同时返回一个 `Option` 类型的值(这种形式的函数在标准库内随处所见),在该函数的内部处理中,如果传入的是一个 `None` ,则返回一个 `None` 且不做任何处理;如果传入的是一个 `Some(i32)`,则通过模式绑定,把其中的值绑定到变量 `i` 上,然后返回 `i+1` 的值,同时用 `Some` 进行包裹。
+`plus_one` 接受一个 `Option` 类型的参数,同时返回一个 `Option` 类型的值(这种形式的函数在标准库内随处所见),在该函数的内部处理中,如果传入的是一个 `None` ,则返回一个 `None` 且不做任何处理;如果传入的是一个 `Some(i32)`,则通过模式绑定,把其中的值绑定到变量 `i` 上,然后返回 `i+1` 的值,同时用 `Some` 进行包裹。
为了进一步说明,假设 `plus_one` 函数接受的参数值 x 是 `Some(5)`,来看看具体的分支匹配情况:
diff --git a/src/basic/match-pattern/pattern-match.md b/src/basic/match-pattern/pattern-match.md
index 3e823445..568afa8e 100644
--- a/src/basic/match-pattern/pattern-match.md
+++ b/src/basic/match-pattern/pattern-match.md
@@ -89,13 +89,13 @@ let PATTERN = EXPRESSION;
let x = 5;
```
-这其中,`x` 也是一种模式绑定,代表将**匹配的值绑定到变量 x 上**。因此,在 Rust 中,**变量名也是一种模式**,只不过它比较朴素很不起眼罢了。
+这其中,`x` 也是一种模式绑定,代表将**匹配的值绑定到变量 x 上**。因此,在 Rust 中,**变量名也是一种模式**,只不过它比较朴素很不起眼罢了。
```rust
let (x, y, z) = (1, 2, 3);
```
-上面将一个元组与模式进行匹配(**模式和值的类型必需相同!**),然后把 `1, 2, 3` 分别绑定到 `x, y, z` 上。
+上面将一个元组与模式进行匹配(**模式和值的类型必需相同!**),然后把 `1, 2, 3` 分别绑定到 `x, y, z` 上。
模式匹配要求两边的类型必须相同,否则就会导致下面的报错:
-从图中可以清晰地看出 `File` 结构体两个字段 `name` 和 `data` 分别拥有底层两个 `[u8]` 数组的所有权(`String` 类型的底层也是 `[u8]` 数组),通过 `ptr` 指针指向底层数组的内存地址,这里你可以把 `ptr` 指针理解为 Rust 中的引用类型。
+从图中可以清晰地看出 `File` 结构体两个字段 `name` 和 `data` 分别拥有底层两个 `[u8]` 数组的所有权(`String` 类型的底层也是 `[u8]` 数组),通过 `ptr` 指针指向底层数组的内存地址,这里你可以把 `ptr` 指针理解为 Rust 中的引用类型。
该图片也侧面印证了:**把结构体中具有所有权的字段转移出去后,将无法再访问该字段,但是可以正常访问其它的字段**。
@@ -206,7 +206,7 @@ println!("{:?}", user1);
还记得之前讲过的基本没啥用的[单元类型](https://course.rs/basic/base-type/char-bool.html#单元类型)吧?单元结构体就跟它很像,没有任何字段和属性,但是好在,它还挺有用。
-如果你定义一个类型,但是不关心该类型的内容, 只关心它的行为时,就可以使用 `单元结构体`:
+如果你定义一个类型,但是不关心该类型的内容,只关心它的行为时,就可以使用 `单元结构体`:
```rust
struct AlwaysEqual;
diff --git a/src/basic/flow-control.md b/src/basic/flow-control.md
index 2f2eef1b..8309a2ac 100644
--- a/src/basic/flow-control.md
+++ b/src/basic/flow-control.md
@@ -8,7 +8,7 @@
> if else 无处不在 -- 鲁迅
-但凡你能找到一门编程语言没有 `if else`,那么一定更要反馈给鲁迅,反正不是我说的:) 总之,只要你拥有其它语言的编程经验,就一定会有以下认知:`if else` **表达式**根据条件执行不同的代码分支:
+但凡你能找到一门编程语言没有 `if else`,那么一定更要反馈给鲁迅,反正不是我说的 :) 总之,只要你拥有其它语言的编程经验,就一定会有以下认知:`if else` **表达式**根据条件执行不同的代码分支:
```rust
if condition == true {
@@ -38,7 +38,7 @@ fn main() {
以上代码有以下几点要注意:
- **`if` 语句块是表达式**,这里我们使用 `if` 表达式的返回值来给 `number` 进行赋值:`number` 的值是 `5`
-- 用 `if` 来赋值时,要保证每个分支返回的类型一样(事实上,这种说法不完全准确,见[这里](https://course.rs/appendix/expressions.html#if表达式)),此处返回的 `5` 和 `6` 就是同一个类型,如果返回类型不一致就会报错
+- 用 `if` 来赋值时,要保证每个分支返回的类型一样(事实上,这种说法不完全准确,见[这里](https://course.rs/appendix/expressions.html#if表达式)),此处返回的 `5` 和 `6` 就是同一个类型,如果返回类型不一致就会报错
```console
error[E0308]: if and else have incompatible types
@@ -118,7 +118,7 @@ for item in &container {
}
```
-> 对于实现了 `copy` 特征的数组(例如 [i32; 10] )而言, `for item in arr` 并不会把 `arr` 的所有权转移,而是直接对其进行了拷贝,因此循环之后仍然可以使用 `arr` 。
+> 对于实现了 `copy` 特征的数组(例如 [i32; 10])而言, `for item in arr` 并不会把 `arr` 的所有权转移,而是直接对其进行了拷贝,因此循环之后仍然可以使用 `arr` 。
如果想在循环中,**修改该元素**,可以使用 `mut` 关键字:
diff --git a/src/basic/match-pattern/match-if-let.md b/src/basic/match-pattern/match-if-let.md
index 8b38ec0b..1c13d13c 100644
--- a/src/basic/match-pattern/match-if-let.md
+++ b/src/basic/match-pattern/match-if-let.md
@@ -144,7 +144,7 @@ fn value_in_cents(coin: Coin) -> u8 {
上面代码中,在匹配 `Coin::Quarter(state)` 模式时,我们把它内部存储的值绑定到了 `state` 变量上,因此 `state` 变量就是对应的 `UsState` 枚举类型。
-例如有一个印了阿拉斯加州标记的 25 分硬币:`Coin::Quarter(UsState::Alaska)`, 它在匹配时,`state` 变量将被绑定 `UsState::Alaska` 的枚举值。
+例如有一个印了阿拉斯加州标记的 25 分硬币:`Coin::Quarter(UsState::Alaska)`,它在匹配时,`state` 变量将被绑定 `UsState::Alaska` 的枚举值。
再来看一个更复杂的例子:
@@ -236,7 +236,7 @@ error[E0004]: non-exhaustive patterns: `West` not covered // 非穷尽匹配,`
= note: the matched value is of type `Direction`
```
-不禁想感叹,Rust 的编译器**真强大**,忍不住想爆粗口了,sorry,如果你以后进一步深入使用 Rust 也会像我这样感叹的。Rust 编译器清晰地知道 `match` 中有哪些分支没有被覆盖, 这种行为能强制我们处理所有的可能性,有效避免传说中价值**十亿美金**的 `null` 陷阱。
+不禁想感叹,Rust 的编译器**真强大**,忍不住想爆粗口了,sorry,如果你以后进一步深入使用 Rust 也会像我这样感叹的。Rust 编译器清晰地知道 `match` 中有哪些分支没有被覆盖,这种行为能强制我们处理所有的可能性,有效避免传说中价值**十亿美金**的 `null` 陷阱。
#### `_` 通配符
@@ -342,7 +342,7 @@ assert!(matches!(bar, Some(x) if x > 2));
## 变量遮蔽
-无论是 `match` 还是 `if let`,这里都是一个新的代码块,而且这里的绑定相当于新变量,如果你使用同名变量,会发生变量遮蔽:
+无论是 `match` 还是 `if let`,这里都是一个新的代码块,而且这里的绑定相当于新变量,如果你使用同名变量,会发生变量遮蔽:
```rust
fn main() {
diff --git a/src/basic/match-pattern/option.md b/src/basic/match-pattern/option.md
index 634a46db..12714b98 100644
--- a/src/basic/match-pattern/option.md
+++ b/src/basic/match-pattern/option.md
@@ -32,7 +32,7 @@ let six = plus_one(five);
let none = plus_one(None);
```
-`plus_one` 接受一个 `Option` 类型的参数,同时返回一个 `Option` 类型的值(这种形式的函数在标准库内随处所见),在该函数的内部处理中,如果传入的是一个 `None` ,则返回一个 `None` 且不做任何处理;如果传入的是一个 `Some(i32)`,则通过模式绑定,把其中的值绑定到变量 `i` 上,然后返回 `i+1` 的值,同时用 `Some` 进行包裹。
+`plus_one` 接受一个 `Option` 类型的参数,同时返回一个 `Option` 类型的值(这种形式的函数在标准库内随处所见),在该函数的内部处理中,如果传入的是一个 `None` ,则返回一个 `None` 且不做任何处理;如果传入的是一个 `Some(i32)`,则通过模式绑定,把其中的值绑定到变量 `i` 上,然后返回 `i+1` 的值,同时用 `Some` 进行包裹。
为了进一步说明,假设 `plus_one` 函数接受的参数值 x 是 `Some(5)`,来看看具体的分支匹配情况:
diff --git a/src/basic/match-pattern/pattern-match.md b/src/basic/match-pattern/pattern-match.md
index 3e823445..568afa8e 100644
--- a/src/basic/match-pattern/pattern-match.md
+++ b/src/basic/match-pattern/pattern-match.md
@@ -89,13 +89,13 @@ let PATTERN = EXPRESSION;
let x = 5;
```
-这其中,`x` 也是一种模式绑定,代表将**匹配的值绑定到变量 x 上**。因此,在 Rust 中,**变量名也是一种模式**,只不过它比较朴素很不起眼罢了。
+这其中,`x` 也是一种模式绑定,代表将**匹配的值绑定到变量 x 上**。因此,在 Rust 中,**变量名也是一种模式**,只不过它比较朴素很不起眼罢了。
```rust
let (x, y, z) = (1, 2, 3);
```
-上面将一个元组与模式进行匹配(**模式和值的类型必需相同!**),然后把 `1, 2, 3` 分别绑定到 `x, y, z` 上。
+上面将一个元组与模式进行匹配(**模式和值的类型必需相同!**),然后把 `1, 2, 3` 分别绑定到 `x, y, z` 上。
模式匹配要求两边的类型必须相同,否则就会导致下面的报错: