diff --git a/contents/advance/concurrency-with-threads/thread.md b/contents/advance/concurrency-with-threads/thread.md
index 85cc02df..ad0e1d2f 100644
--- a/contents/advance/concurrency-with-threads/thread.md
+++ b/contents/advance/concurrency-with-threads/thread.md
@@ -34,7 +34,7 @@ fn main() {
有几点值得注意:
- 线程内部的代码使用闭包来执行
- `main` 线程一旦结束,程序就立刻结束,因此需要保持它的存活,直到其它子线程完成自己的任务
-- `thread::sleep` 会让当前线程休眠指定的时间,随后其它线程会被调度运行(上一节并发与并行中有简单介绍过),因此就算你的电脑只有一个 CPU 核心,该程序也会表现的如同多 CPU 核心一般,这就是并发!
+- `thread::sleep` 会让当前线程休眠指定的时间,随后其它线程会被调度运行(上一节并发与并行中有简单介绍过),因此就算你的电脑只有一个 CPU 核心,该程序也会表现的如同多 CPU 核心一般,这就是并发!
来看看输出:
```console
@@ -91,7 +91,7 @@ hi number 4 from the main thread!
以上输出清晰的展示了线程阻塞的作用,如果你将 `handle.join` 放置在 `main` 线程中的 `for` 循环后面,那就是另外一个结果:两个线程交替输出。
## 在线程闭包中使用 move
-在[闭包章节](../../advance/functional-programing/closure.md#move和Fn)中,有讲过 `move` 关键字在闭包中的使用可以让该闭包拿走环境中某个值的所有权,同样地,你可以使用 `move` 来将所有权从一个线程转移到另外一个线程。
+在[闭包](https://course.rs/advance/functional-programing/closure.html#move-和-fn)章节中,有讲过 `move` 关键字在闭包中的使用可以让该闭包拿走环境中某个值的所有权,同样地,你可以使用 `move` 来将所有权从一个线程转移到另外一个线程。
首先,来看看在一个线程中直接使用另一个线程中的数据会如何:
```rust
@@ -132,7 +132,7 @@ help: to force the closure to take ownership of `v` (and any other referenced va
| ++++
```
-其实代码本身并没有什么问题,问题在于 Rust 无法确定新的线程会活多久(多个线程的结束顺序并不是固定的),所以也无法确定新线程所引用的 `v` 是否在使用过程中一直合法:
+其实代码本身并没有什么问题,问题在于 Rust 无法确定新的线程会活多久(多个线程的结束顺序并不是固定的),所以也无法确定新线程所引用的 `v` 是否在使用过程中一直合法:
```rust
use std::thread;
@@ -206,7 +206,7 @@ fn main() {
以上代码中,`main` 线程创建了一个新的线程 `A`,同时该新线程又创建了一个新的线程 `B`,可以看到 `A` 线程在创建完 `B` 线程后就立即结束了,而 `B` 线程则在不停地循环输出。
-从之前的线程结束规则,我们可以猜测程序将这样执行:`A` 线程结束后,由它创建的 `B` 线程仍在疯狂输出,直到 `main` 线程在100毫秒后结束。如果你把该时间增加到几十秒,就可以看到你的 CPU 核心 100% 的盛况了-,-
+从之前的线程结束规则,我们可以猜测程序将这样执行:`A` 线程结束后,由它创建的 `B` 线程仍在疯狂输出,直到 `main` 线程在 100 毫秒后结束。如果你把该时间增加到几十秒,就可以看到你的 CPU 核心 100% 的盛况了-,-
## 多线程的性能
@@ -218,10 +218,10 @@ fn main() {
#### 创建多少线程合适
因为 CPU 的核心数限制,当任务是 CPU 密集型时,就算线程数超过了 CPU 核心数,也并不能帮你获得更好的性能,因为每个线程的任务都可以轻松让 CPU 的某个核心跑满,既然如此,让线程数等于 CPU 核心数是最好的。
-但是当你的任务大部分时间都处于阻塞状态时,就可以考虑增多线程数量,这样当某个线程处于阻塞状态时,会被切走,进而运行其它的线程,典型就是网络 IO 操作,我们可以为每一个进来的用户连接创建一个线程去处理,该连接绝大部分时间都是处于 IO 读取阻塞状态,因此有限的 CPU 核心完全可以处理成百上千的用户连接线程,但是事实上,对于这种网络 IO 情况,一般都不再使用多线程的方式了,毕竟操作系统的线程数是有限的,意味着并发数也很容易达到上限,而且过多的线程也会导致线程上下文切换的代价过大,使用 async/await 的 `M:N` 并发模型,就没有这个烦恼。
+但是当你的任务大部分时间都处于阻塞状态时,就可以考虑增多线程数量,这样当某个线程处于阻塞状态时,会被切走,进而运行其它的线程,典型就是网络 IO 操作,我们可以为每一个进来的用户连接创建一个线程去处理,该连接绝大部分时间都是处于 IO 读取阻塞状态,因此有限的 CPU 核心完全可以处理成百上千的用户连接线程,但是事实上,对于这种网络 IO 情况,一般都不再使用多线程的方式了,毕竟操作系统的线程数是有限的,意味着并发数也很容易达到上限,而且过多的线程也会导致线程上下文切换的代价过大,使用 `async/await` 的 `M:N` 并发模型,就没有这个烦恼。
#### 多线程的开销
-下面的代码是一个无锁实现(CAS)的 Hashmap 在多线程下的使用:
+下面的代码是一个无锁实现(CAS)的 `Hashmap` 在多线程下的使用:
```rust
for i in 0..num_threads {
let ht = Arc::clone(&ht);
@@ -248,7 +248,7 @@ for handle in handles {
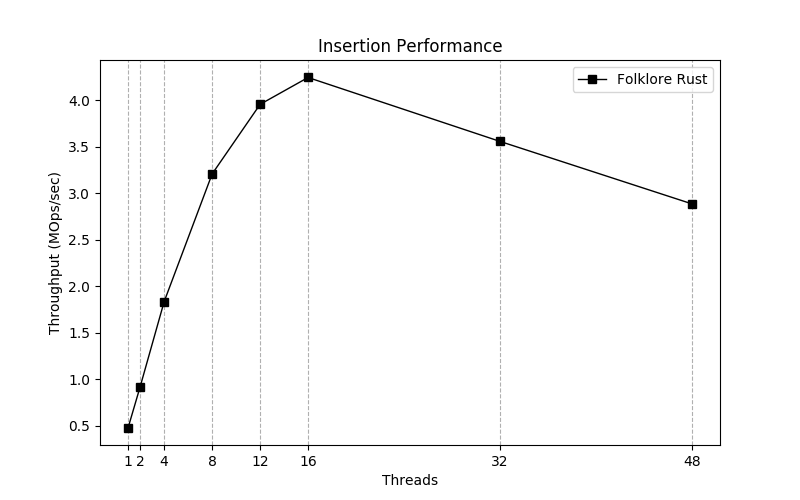 -从图上可以明显的看出: 吞吐并不是线性增长,尤其从 `16` 核开始,甚至开始肉眼可见的下降,这是为什么呢?
+从图上可以明显的看出:吞吐并不是线性增长,尤其从 `16` 核开始,甚至开始肉眼可见的下降,这是为什么呢?
限于书本的篇幅有限,我们只能给出大概的原因:
@@ -333,9 +333,9 @@ FOO.with(|f| {
});
```
-上面代码中,`FOO`即是我们创建的**线程局部变量**,每个新的线程访问它时,都会使用它的初始值作为开始,各个线程中的`FOO`值彼此互不干扰。注意`FOO`使用`static`声明为生命周期为`'static`的静态变量。
+上面代码中,`FOO` 即是我们创建的**线程局部变量**,每个新的线程访问它时,都会使用它的初始值作为开始,各个线程中的 `FOO` 值彼此互不干扰。注意 `FOO` 使用 `static` 声明为生命周期为 `'static` 的静态变量。
-可以注意到,线程中对`FOO`的使用是通过借用的方式,但是若我们需要每个线程独自获取它的拷贝,最后进行汇总,就有些强人所难了。
+可以注意到,线程中对 `FOO` 的使用是通过借用的方式,但是若我们需要每个线程独自获取它的拷贝,最后进行汇总,就有些强人所难了。
你还可以在结构体中使用线程局部变量:
```rust
@@ -374,7 +374,7 @@ impl Bar {
```
#### 三方库 thread-local
-除了标准库外,一位大神还开发了[thread-local](https://github.com/Amanieu/thread_local-rs)库,它允许每个线程持有值的独立拷贝:
+除了标准库外,一位大神还开发了 [thread-local](https://github.com/Amanieu/thread_local-rs) 库,它允许每个线程持有值的独立拷贝:
```rust
use thread_local::ThreadLocal;
use std::sync::Arc;
@@ -434,8 +434,8 @@ fn main() {
上述代码流程如下:
-1. `main`线程首先进入`while`循环,调用`wait`方法挂起等待子线程的通知,并释放了锁`started`
-2. 子线程获取到锁,并将其修改为true, 然后调用条件变量的`notify_one`方法来通知主线程继续执行
+1. `main` 线程首先进入 `while` 循环,调用 `wait` 方法挂起等待子线程的通知,并释放了锁 `started`
+2. 子线程获取到锁,并将其修改为 `true`,然后调用条件变量的 `notify_one` 方法来通知主线程继续执行
## 只被调用一次的函数
有时,我们会需要某个函数在多线程环境下只被调用一次,例如初始化全局变量,无论是哪个线程先调用函数来初始化,都会保证全局变量只会被初始化一次,随后的其它线程调用就会忽略该函数:
@@ -470,7 +470,7 @@ fn main() {
}
```
-代码运行的结果取决于哪个线程先调用 `INIT.call_once` (虽然代码具有先后顺序,但是线程的初始化顺序并无法被保证!因为线程初始化是异步的,且耗时较久),若 `handle1` 先,则输出 `1`,否则输出 `2`。
+代码运行的结果取决于哪个线程先调用 `INIT.call_once` (虽然代码具有先后顺序,但是线程的初始化顺序并无法被保证!因为线程初始化是异步的,且耗时较久),若 `handle1` 先,则输出 `1`,否则输出 `2`。
**call_once 方法**
@@ -482,7 +482,7 @@ fn main() {
## 总结
-[Rust的线程模型](./intro.md)是 `1:1` 模型,因为 Rust 要保持尽量小的运行时。
+[Rust 的线程模型](./intro.md)是 `1:1` 模型,因为 Rust 要保持尽量小的运行时。
我们可以使用 `thread::spawn` 来创建线程,创建出的多个线程之间并不存在执行顺序关系,因此代码逻辑千万不要依赖于线程间的执行顺序。
diff --git a/contents/advance/functional-programing/closure.md b/contents/advance/functional-programing/closure.md
index 51da26cb..c4e5f83a 100644
--- a/contents/advance/functional-programing/closure.md
+++ b/contents/advance/functional-programing/closure.md
@@ -1,4 +1,4 @@
-# 闭包closure
+# 闭包 Closure
闭包这个词语由来已久,自上世纪 60 年代就由 `Scheme` 语言引进之后,被广泛用于函数式编程语言中,进入 21 世纪后,各种现代化的编程语言也都不约而同地把闭包作为核心特性纳入到语言设计中来。那么到底何为闭包?
@@ -18,7 +18,7 @@ fn main() {
## 使用闭包来简化代码
-#### 传统函数实现
+### 传统函数实现
想象一下,我们要进行健身,用代码怎么实现(写代码什么鬼,健身难道不应该去健身房嘛?答曰:健身太累了,还是虚拟健身好,点到为止)?这里是我的想法:
```rust
use std::thread;
@@ -334,10 +334,10 @@ error[E0434]: can't capture dynamic environment in a fn item // 在函数中无
如上所示,编译器准确地告诉了我们错误,甚至同时给出了提示:使用闭包来替代函数,这种聪明令我有些无所适从,总感觉会显得我很笨。
-#### 闭包对内存的影响
+### 闭包对内存的影响
当闭包从环境中捕获一个值时,会分配内存去存储这些值。对于有些场景来说,这种额外的内存分配会成为一种负担。与之相比,函数就不会去捕获这些环境值,因此定义和使用函数不会拥有这种内存负担。
-#### 三种 Fn 特征
+### 三种 Fn 特征
闭包捕获变量有三种途径,恰好对应函数参数的三种传入方式:转移所有权、可变借用、不可变借用,因此相应的 `Fn` 特征也有三种:
1. `FnOnce`,该类型的闭包会拿走被捕获变量的所有权。`Once` 顾名思义,说明该闭包只能运行一次:
@@ -512,7 +512,7 @@ fn exec<'a, F: Fn(String) -> ()>(f: F) {
在这里,因为无需改变 `s`,因此闭包中只对 `s` 进行了不可变借用,那么在 `exec` 中,将其标记为 `Fn` 特征就完全正确。
-##### move 和 Fn
+#### move 和 Fn
在上面,我们讲到了 `move` 关键字对于 `FnOnce` 特征的重要性,但是实际上使用了 `move` 的闭包依然可能实现了 `Fn` 或 `FnMut` 特征。
因为,**一个闭包实现了哪种 Fn 特征取决于该闭包如何使用被捕获的变量,而不是取决于闭包如何捕获它们**。`move` 本身强调的就是后者,闭包如何捕获变量:
@@ -547,7 +547,7 @@ fn exec(f: F) {
}
```
-##### 三种 Fn 的关系
+#### 三种 Fn 的关系
实际上,一个闭包并不仅仅实现某一种 `Fn` 特征,规则如下:
- 所有的闭包都自动实现了 `FnOnce` 特征,因此任何一个闭包都至少可以被调用一次
-从图上可以明显的看出: 吞吐并不是线性增长,尤其从 `16` 核开始,甚至开始肉眼可见的下降,这是为什么呢?
+从图上可以明显的看出:吞吐并不是线性增长,尤其从 `16` 核开始,甚至开始肉眼可见的下降,这是为什么呢?
限于书本的篇幅有限,我们只能给出大概的原因:
@@ -333,9 +333,9 @@ FOO.with(|f| {
});
```
-上面代码中,`FOO`即是我们创建的**线程局部变量**,每个新的线程访问它时,都会使用它的初始值作为开始,各个线程中的`FOO`值彼此互不干扰。注意`FOO`使用`static`声明为生命周期为`'static`的静态变量。
+上面代码中,`FOO` 即是我们创建的**线程局部变量**,每个新的线程访问它时,都会使用它的初始值作为开始,各个线程中的 `FOO` 值彼此互不干扰。注意 `FOO` 使用 `static` 声明为生命周期为 `'static` 的静态变量。
-可以注意到,线程中对`FOO`的使用是通过借用的方式,但是若我们需要每个线程独自获取它的拷贝,最后进行汇总,就有些强人所难了。
+可以注意到,线程中对 `FOO` 的使用是通过借用的方式,但是若我们需要每个线程独自获取它的拷贝,最后进行汇总,就有些强人所难了。
你还可以在结构体中使用线程局部变量:
```rust
@@ -374,7 +374,7 @@ impl Bar {
```
#### 三方库 thread-local
-除了标准库外,一位大神还开发了[thread-local](https://github.com/Amanieu/thread_local-rs)库,它允许每个线程持有值的独立拷贝:
+除了标准库外,一位大神还开发了 [thread-local](https://github.com/Amanieu/thread_local-rs) 库,它允许每个线程持有值的独立拷贝:
```rust
use thread_local::ThreadLocal;
use std::sync::Arc;
@@ -434,8 +434,8 @@ fn main() {
上述代码流程如下:
-1. `main`线程首先进入`while`循环,调用`wait`方法挂起等待子线程的通知,并释放了锁`started`
-2. 子线程获取到锁,并将其修改为true, 然后调用条件变量的`notify_one`方法来通知主线程继续执行
+1. `main` 线程首先进入 `while` 循环,调用 `wait` 方法挂起等待子线程的通知,并释放了锁 `started`
+2. 子线程获取到锁,并将其修改为 `true`,然后调用条件变量的 `notify_one` 方法来通知主线程继续执行
## 只被调用一次的函数
有时,我们会需要某个函数在多线程环境下只被调用一次,例如初始化全局变量,无论是哪个线程先调用函数来初始化,都会保证全局变量只会被初始化一次,随后的其它线程调用就会忽略该函数:
@@ -470,7 +470,7 @@ fn main() {
}
```
-代码运行的结果取决于哪个线程先调用 `INIT.call_once` (虽然代码具有先后顺序,但是线程的初始化顺序并无法被保证!因为线程初始化是异步的,且耗时较久),若 `handle1` 先,则输出 `1`,否则输出 `2`。
+代码运行的结果取决于哪个线程先调用 `INIT.call_once` (虽然代码具有先后顺序,但是线程的初始化顺序并无法被保证!因为线程初始化是异步的,且耗时较久),若 `handle1` 先,则输出 `1`,否则输出 `2`。
**call_once 方法**
@@ -482,7 +482,7 @@ fn main() {
## 总结
-[Rust的线程模型](./intro.md)是 `1:1` 模型,因为 Rust 要保持尽量小的运行时。
+[Rust 的线程模型](./intro.md)是 `1:1` 模型,因为 Rust 要保持尽量小的运行时。
我们可以使用 `thread::spawn` 来创建线程,创建出的多个线程之间并不存在执行顺序关系,因此代码逻辑千万不要依赖于线程间的执行顺序。
diff --git a/contents/advance/functional-programing/closure.md b/contents/advance/functional-programing/closure.md
index 51da26cb..c4e5f83a 100644
--- a/contents/advance/functional-programing/closure.md
+++ b/contents/advance/functional-programing/closure.md
@@ -1,4 +1,4 @@
-# 闭包closure
+# 闭包 Closure
闭包这个词语由来已久,自上世纪 60 年代就由 `Scheme` 语言引进之后,被广泛用于函数式编程语言中,进入 21 世纪后,各种现代化的编程语言也都不约而同地把闭包作为核心特性纳入到语言设计中来。那么到底何为闭包?
@@ -18,7 +18,7 @@ fn main() {
## 使用闭包来简化代码
-#### 传统函数实现
+### 传统函数实现
想象一下,我们要进行健身,用代码怎么实现(写代码什么鬼,健身难道不应该去健身房嘛?答曰:健身太累了,还是虚拟健身好,点到为止)?这里是我的想法:
```rust
use std::thread;
@@ -334,10 +334,10 @@ error[E0434]: can't capture dynamic environment in a fn item // 在函数中无
如上所示,编译器准确地告诉了我们错误,甚至同时给出了提示:使用闭包来替代函数,这种聪明令我有些无所适从,总感觉会显得我很笨。
-#### 闭包对内存的影响
+### 闭包对内存的影响
当闭包从环境中捕获一个值时,会分配内存去存储这些值。对于有些场景来说,这种额外的内存分配会成为一种负担。与之相比,函数就不会去捕获这些环境值,因此定义和使用函数不会拥有这种内存负担。
-#### 三种 Fn 特征
+### 三种 Fn 特征
闭包捕获变量有三种途径,恰好对应函数参数的三种传入方式:转移所有权、可变借用、不可变借用,因此相应的 `Fn` 特征也有三种:
1. `FnOnce`,该类型的闭包会拿走被捕获变量的所有权。`Once` 顾名思义,说明该闭包只能运行一次:
@@ -512,7 +512,7 @@ fn exec<'a, F: Fn(String) -> ()>(f: F) {
在这里,因为无需改变 `s`,因此闭包中只对 `s` 进行了不可变借用,那么在 `exec` 中,将其标记为 `Fn` 特征就完全正确。
-##### move 和 Fn
+#### move 和 Fn
在上面,我们讲到了 `move` 关键字对于 `FnOnce` 特征的重要性,但是实际上使用了 `move` 的闭包依然可能实现了 `Fn` 或 `FnMut` 特征。
因为,**一个闭包实现了哪种 Fn 特征取决于该闭包如何使用被捕获的变量,而不是取决于闭包如何捕获它们**。`move` 本身强调的就是后者,闭包如何捕获变量:
@@ -547,7 +547,7 @@ fn exec(f: F) {
}
```
-##### 三种 Fn 的关系
+#### 三种 Fn 的关系
实际上,一个闭包并不仅仅实现某一种 `Fn` 特征,规则如下:
- 所有的闭包都自动实现了 `FnOnce` 特征,因此任何一个闭包都至少可以被调用一次