diff --git a/src/basic/base-type/function.md b/src/basic/base-type/function.md
index 20ad904e..bcd9133e 100644
--- a/src/basic/base-type/function.md
+++ b/src/basic/base-type/function.md
@@ -10,7 +10,7 @@ fn add(i: i32, j: i32) -> i32 {
}
```
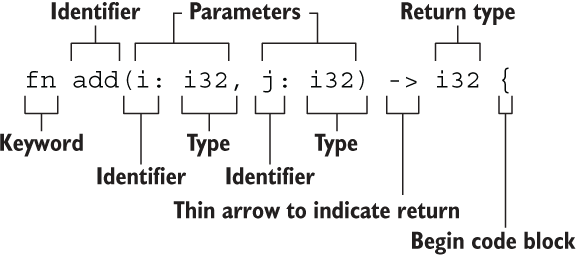
-该函数如此简单,但是又是如此的五脏俱全,声明函数的关键字 `fn` ,函数名 `add()`,参数 `i` 和 `j`,参数类型和返回值类型都是 `i32`,总之一切那么的普通,但是又那么的自信,直到你看到了下面这张图:
+该函数如此简单,但是又是如此的五脏俱全,声明函数的关键字 `fn`,函数名 `add()`,参数 `i` 和 `j`,参数类型和返回值类型都是 `i32`,总之一切那么的普通,但是又那么的自信,直到你看到了下面这张图:
 diff --git a/src/basic/base-type/index.md b/src/basic/base-type/index.md
index d5c0d86e..94743d8d 100644
--- a/src/basic/base-type/index.md
+++ b/src/basic/base-type/index.md
@@ -1,18 +1,18 @@
# 基本类型
-当一门语言不谈类型时,你得小心,这大概率是动态语言(别拍我,我承认是废话)。但是把类型大张旗鼓的用多个章节去讲的,Rust 是其中之一。
+当一门语言不谈类型时,你得小心,这大概率是动态语言(别拍我,我承认是废话)。但是把类型大张旗鼓的用多个章节去讲的,Rust 是其中之一。
-Rust 每个值都有其确切的数据类型,总的来说可以分为两类:基本类型和复合类型。 基本类型意味着它们往往是一个最小化原子类型,无法解构为其它类型(一般意义上来说),由以下组成:
+Rust 每个值都有其确切的数据类型,总的来说可以分为两类:基本类型和复合类型。 基本类型意味着它们往往是一个最小化原子类型,无法解构为其它类型(一般意义上来说),由以下组成:
-- 数值类型: 有符号整数 (`i8`, `i16`, `i32`, `i64`, `isize`)、 无符号整数 (`u8`, `u16`, `u32`, `u64`, `usize`) 、浮点数 (`f32`, `f64`)、以及有理数、复数
+- 数值类型:有符号整数 (`i8`, `i16`, `i32`, `i64`, `isize`)、 无符号整数 (`u8`, `u16`, `u32`, `u64`, `usize`) 、浮点数 (`f32`, `f64`)、以及有理数、复数
- 字符串:字符串字面量和字符串切片 `&str`
-- 布尔类型: `true`和`false`
-- 字符类型: 表示单个 Unicode 字符,存储为 4 个字节
-- 单元类型: 即 `()` ,其唯一的值也是 `()`
+- 布尔类型:`true` 和 `false`
+- 字符类型:表示单个 Unicode 字符,存储为 4 个字节
+- 单元类型:即 `()` ,其唯一的值也是 `()`
## 类型推导与标注
-与 Python、JavaScript 等动态语言不同,Rust 是一门静态类型语言,也就是编译器必须在编译期知道我们所有变量的类型,但这不意味着你需要为每个变量指定类型,因为 **Rust 编译器很聪明,它可以根据变量的值和上下文中的使用方式来自动推导出变量的类型**,同时编译器也不够聪明,在某些情况下,它无法推导出变量类型,需要手动去给予一个类型标注,关于这一点在 [Rust 语言初印象](https://course.rs/first-try/hello-world.html#rust-语言初印象)中有过展示。
+与 Python、JavaScript 等动态语言不同,Rust 是一门静态类型语言,也就是编译器必须在编译期知道我们所有变量的类型,但这不意味着你需要为每个变量指定类型,因为 **Rust 编译器很聪明,它可以根据变量的值和上下文中的使用方式来自动推导出变量的类型**,同时编译器也不够聪明,在某些情况下,它无法推导出变量类型,需要手动去给予一个类型标注,关于这一点在 [Rust 语言初印象](https://course.rs/first-try/hello-world.html#rust-语言初印象) 中有过展示。
来看段代码:
diff --git a/src/basic/base-type/numbers.md b/src/basic/base-type/numbers.md
index b9ba7175..25d47350 100644
--- a/src/basic/base-type/numbers.md
+++ b/src/basic/base-type/numbers.md
@@ -22,7 +22,7 @@ Rust 使用一个相对传统的语法来创建整数(`1`,`2`,...)和浮
| 128 位 | `i128` | `u128` |
| 视架构而定 | `isize` | `usize` |
-类型定义的形式统一为:`有无符号 + 类型大小(位数)`。**无符号数**表示数字只能取正数和0,而**有符号**则表示数字可以取正数、负数还有0。就像在纸上写数字一样:当要强调符号时,数字前面可以带上正号或负号;然而,当很明显确定数字为正数时,就不需要加上正号了。有符号数字以[补码](https://en.wikipedia.org/wiki/Two%27s_complement)形式存储。
+类型定义的形式统一为:`有无符号 + 类型大小(位数)`。**无符号数**表示数字只能取正数和 0,而**有符号**则表示数字可以取正数、负数还有 0。就像在纸上写数字一样:当要强调符号时,数字前面可以带上正号或负号;然而,当很明显确定数字为正数时,就不需要加上正号了。有符号数字以[补码](https://en.wikipedia.org/wiki/Two%27s_complement)形式存储。
每个有符号类型规定的数字范围是 -(2n - 1) ~ 2n -
1 - 1,其中 `n` 是该定义形式的位长度。因此 `i8` 可存储数字范围是 -(27) ~ 27 - 1,即 -128 ~ 127。无符号类型可以存储的数字范围是 0 ~ 2n - 1,所以 `u8` 能够存储的数字为 0 ~ 28 - 1,即 0 ~ 255。
@@ -112,7 +112,7 @@ fn main() {
}
```
-你可能以为,这段代码没啥问题吧,实际上它会 _panic_(程序崩溃,抛出异常),因为二进制精度问题,导致了 0.1 + 0.2 并不严格等于 0.3,它们可能在小数点 N 位后存在误差。
+你可能以为,这段代码没啥问题吧,实际上它会 _panic_(程序崩溃,抛出异常),因为二进制精度问题,导致了 0.1 + 0.2 并不严格等于 0.3,它们可能在小数点 N 位后存在误差。
那如果非要进行比较呢?可以考虑用这种方式 `(0.1_f64 + 0.2 - 0.3).abs() < 0.00001` ,具体小于多少,取决于你对精度的需求。
@@ -161,7 +161,7 @@ note: run with `RUST_BACKTRACE=1` environment variable to display
#### NaN
-对于数学上未定义的结果,例如对负数取平方根 `-42.1.sqrt()` ,会产生一个特殊的结果:Rust 的浮点数类型使用 `NaN` (not a number)来处理这些情况。
+对于数学上未定义的结果,例如对负数取平方根 `-42.1.sqrt()` ,会产生一个特殊的结果:Rust 的浮点数类型使用 `NaN` (not a number) 来处理这些情况。
**所有跟 `NaN` 交互的操作,都会返回一个 `NaN`**,而且 `NaN` 不能用来比较,下面的代码会崩溃:
@@ -243,7 +243,7 @@ fn main() {
## 位运算
-Rust的位运算基本上和其他语言一样
+Rust 的位运算基本上和其他语言一样
| 运算符 | 说明 |
| ------- | ------------------------------------------------------ |
diff --git a/src/basic/base-type/statement-expression.md b/src/basic/base-type/statement-expression.md
index b13e027b..31acf29e 100644
--- a/src/basic/base-type/statement-expression.md
+++ b/src/basic/base-type/statement-expression.md
@@ -14,7 +14,7 @@ fn add_with_extra(x: i32, y: i32) -> i32 {
-对于 Rust 语言而言,**这种基于语句(statement)和表达式(expression)的方式是非常重要的,你需要能明确的区分这两个概念**, 但是对于很多其它语言而言,这两个往往无需区分。基于表达式是函数式语言的重要特征,**表达式总要返回值**。
+对于 Rust 语言而言,**这种基于语句(statement)和表达式(expression)的方式是非常重要的,你需要能明确的区分这两个概念**,但是对于很多其它语言而言,这两个往往无需区分。基于表达式是函数式语言的重要特征,**表达式总要返回值**。
其实,在此之前,我们已经多次使用过语句和表达式。
diff --git a/src/basic/ownership/borrowing.md b/src/basic/ownership/borrowing.md
index b5a79474..58f5db0d 100644
--- a/src/basic/ownership/borrowing.md
+++ b/src/basic/ownership/borrowing.md
@@ -225,7 +225,7 @@ fn main() {
// 新编译器中,r3作用域在这里结束
```
-在老版本的编译器中(Rust 1.31 前),将会报错,因为 `r1` 和 `r2` 的作用域在花括号 `}` 处结束,那么 `r3` 的借用就会触发 **无法同时借用可变和不可变**的规则。
+在老版本的编译器中(Rust 1.31 前),将会报错,因为 `r1` 和 `r2` 的作用域在花括号 `}` 处结束,那么 `r3` 的借用就会触发 **无法同时借用可变和不可变** 的规则。
但是在新的编译器中,该代码将顺利通过,因为 **引用作用域的结束位置从花括号变成最后一次使用的位置**,因此 `r1` 借用和 `r2` 借用在 `println!` 后,就结束了,此时 `r3` 可以顺利借用到可变引用。
@@ -307,7 +307,7 @@ fn no_dangle() -> String {
总的来说,借用规则如下:
-- 同一时刻,你只能拥有要么一个可变引用, 要么任意多个不可变引用
+- 同一时刻,你只能拥有要么一个可变引用,要么任意多个不可变引用
- 引用必须总是有效的
## 课后练习
diff --git a/src/basic/ownership/ownership.md b/src/basic/ownership/ownership.md
index 990f34be..c5458bf6 100644
--- a/src/basic/ownership/ownership.md
+++ b/src/basic/ownership/ownership.md
@@ -23,17 +23,17 @@ int* foo() {
} // 变量a和c的作用域结束
```
-这段代码虽然可以编译通过,但是其实非常糟糕,变量 `a` 和 `c` 都是局部变量,函数结束后将局部变量 `a` 的地址返回,但局部变量 `a` 存在栈中,在离开作用域后,`a` 所申请的栈上内存都会被系统回收,从而造成了 `悬空指针(Dangling Pointer)` 的问题。这是一个非常典型的内存安全问题,虽然编译可以通过,但是运行的时候会出现错误, 很多编程语言都存在。
+这段代码虽然可以编译通过,但是其实非常糟糕,变量 `a` 和 `c` 都是局部变量,函数结束后将局部变量 `a` 的地址返回,但局部变量 `a` 存在栈中,在离开作用域后,`a` 所申请的栈上内存都会被系统回收,从而造成了 `悬空指针(Dangling Pointer)` 的问题。这是一个非常典型的内存安全问题,虽然编译可以通过,但是运行的时候会出现错误,很多编程语言都存在。
再来看变量 `c`,`c` 的值是常量字符串,存储于常量区,可能这个函数我们只调用了一次,也可能我们不再会使用这个字符串,但 `"xyz"` 只有当整个程序结束后系统才能回收这片内存。
-所以内存安全问题,一直都是程序员非常头疼的问题,好在, 在 Rust 中这些问题即将成为历史,因为 Rust 在编译的时候就可以帮助我们发现内存不安全的问题,那 Rust 如何做到这一点呢?
+所以内存安全问题,一直都是程序员非常头疼的问题,好在,在 Rust 中这些问题即将成为历史,因为 Rust 在编译的时候就可以帮助我们发现内存不安全的问题,那 Rust 如何做到这一点呢?
在正式进入主题前,先来一个预热知识。
## 栈(Stack)与堆(Heap)
-栈和堆是编程语言最核心的数据结构,但是在很多语言中,你并不需要深入了解栈与堆。 但对于 Rust 这样的系统编程语言,值是位于栈上还是堆上非常重要, 因为这会影响程序的行为和性能。
+栈和堆是编程语言最核心的数据结构,但是在很多语言中,你并不需要深入了解栈与堆。 但对于 Rust 这样的系统编程语言,值是位于栈上还是堆上非常重要,因为这会影响程序的行为和性能。
栈和堆的核心目标就是为程序在运行时提供可供使用的内存空间。
@@ -49,11 +49,11 @@ int* foo() {
与栈不同,对于大小未知或者可能变化的数据,我们需要将它存储在堆上。
-当向堆上放入数据时,需要请求一定大小的内存空间。操作系统在堆的某处找到一块足够大的空位,把它标记为已使用,并返回一个表示该位置地址的**指针**, 该过程被称为**在堆上分配内存**,有时简称为 “分配”(allocating)。
+当向堆上放入数据时,需要请求一定大小的内存空间。操作系统在堆的某处找到一块足够大的空位,把它标记为已使用,并返回一个表示该位置地址的**指针**,该过程被称为**在堆上分配内存**,有时简称为 “分配”(allocating)。
接着,该指针会被推入**栈**中,因为指针的大小是已知且固定的,在后续使用过程中,你将通过栈中的**指针**,来获取数据在堆上的实际内存位置,进而访问该数据。
-由上可知,堆是一种缺乏组织的数据结构。想象一下去餐馆就座吃饭: 进入餐馆,告知服务员有几个人,然后服务员找到一个够大的空桌子(堆上分配的内存空间)并领你们过去。如果有人来迟了,他们也可以通过桌号(栈上的指针)来找到你们坐在哪。
+由上可知,堆是一种缺乏组织的数据结构。想象一下去餐馆就座吃饭:进入餐馆,告知服务员有几个人,然后服务员找到一个够大的空桌子(堆上分配的内存空间)并领你们过去。如果有人来迟了,他们也可以通过桌号(栈上的指针)来找到你们坐在哪。
#### 性能区别
@@ -74,12 +74,12 @@ int* foo() {
> 1. Rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者
> 2. 一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者
-> 3. 当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
+> 3. 当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
#### 变量作用域
-作用域是一个变量在程序中有效的范围, 假如有这样一个变量:
+作用域是一个变量在程序中有效的范围,假如有这样一个变量:
```rust
let s = "hello";
@@ -106,7 +106,7 @@ let s = "hello";
- **字符串字面值是不可变的**,因为被硬编码到程序代码中
- 并非所有字符串的值都能在编写代码时得知
-例如,字符串是需要程序运行时,通过用户动态输入然后存储在内存中的,这种情况,字符串字面值就完全无用武之地。 为此,Rust 为我们提供动态字符串类型: `String`, 该类型被分配到堆上,因此可以动态伸缩,也就能存储在编译时大小未知的文本。
+例如,字符串是需要程序运行时,通过用户动态输入然后存储在内存中的,这种情况,字符串字面值就完全无用武之地。 为此,Rust 为我们提供动态字符串类型: `String`,该类型被分配到堆上,因此可以动态伸缩,也就能存储在编译时大小未知的文本。
可以使用下面的方法基于字符串字面量来创建 `String` 类型:
@@ -139,7 +139,7 @@ let y = x;
这段代码并没有发生所有权的转移,原因很简单: 代码首先将 `5` 绑定到变量 `x`,接着**拷贝** `x` 的值赋给 `y`,最终 `x` 和 `y` 都等于 `5`,因为整数是 Rust 基本数据类型,是固定大小的简单值,因此这两个值都是通过**自动拷贝**的方式来赋值的,都被存在栈中,完全无需在堆上分配内存。
-整个过程中的赋值都是通过值拷贝的方式完成(发生在栈中),因此并不需要所有权转移。
+整个过程中的赋值都是通过值拷贝的方式完成(发生在栈中),因此并不需要所有权转移。
> 可能有同学会有疑问:这种拷贝不消耗性能吗?实际上,这种栈上的数据足够简单,而且拷贝非常非常快,只需要复制一个整数大小(`i32`,4 个字节)的内存即可,因此在这种情况下,拷贝的速度远比在堆上创建内存来得快的多。实际上,上一章我们讲到的 Rust 基本类型都是通过自动拷贝的方式来赋值的,就像上面代码一样。
@@ -204,7 +204,7 @@ For more information about this error, try `rustc --explain E0382`.
> 1. Rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者
> 2. 一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者
-> 3. 当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
+> 3. 当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
如果你在其他语言中听说过术语 **浅拷贝(shallow copy)** 和 **深拷贝(deep copy)**,那么拷贝指针、长度和容量而不拷贝数据听起来就像浅拷贝,但是又因为 Rust 同时使第一个变量 `s1` 无效了,因此这个操作被称为 **移动(move)**,而不是浅拷贝。上面的例子可以解读为 `s1` 被**移动**到了 `s2` 中。那么具体发生了什么,用一张图简单说明:
@@ -243,7 +243,7 @@ println!("s1 = {}, s2 = {}", s1, s2);
这段代码能够正常运行,说明 `s2` 确实完整的复制了 `s1` 的数据。
-如果代码性能无关紧要,例如初始化程序时或者在某段时间只会执行寥寥数次时,你可以使用 `clone` 来简化编程。但是对于执行较为频繁的代码(热点路径),使用 `clone` 会极大的降低程序性能,需要小心使用!
+如果代码性能无关紧要,例如初始化程序时或者在某段时间只会执行寥寥数次时,你可以使用 `clone` 来简化编程。但是对于执行较为频繁的代码(热点路径),使用 `clone` 会极大的降低程序性能,需要小心使用!
#### 拷贝(浅拷贝)
@@ -271,7 +271,7 @@ Rust 有一个叫做 `Copy` 的特征,可以用在类似整型这样在栈中
- 所有浮点数类型,比如 `f64`
- 字符类型,`char`
- 元组,当且仅当其包含的类型也都是 `Copy` 的时候。比如,`(i32, i32)` 是 `Copy` 的,但 `(i32, String)` 就不是
-- 不可变引用 `&T` ,例如[转移所有权](#转移所有权)中的最后一个例子,**但是注意: 可变引用 `&mut T` 是不可以 Copy的**
+- 不可变引用 `&T` ,例如[转移所有权](#转移所有权)中的最后一个例子,**但是注意:可变引用 `&mut T` 是不可以 Copy的**
## 函数传值与返回
diff --git a/src/basic/variable.md b/src/basic/variable.md
index a6e5470a..e815af09 100644
--- a/src/basic/variable.md
+++ b/src/basic/variable.md
@@ -4,7 +4,7 @@
## 为何要手动设置变量的可变性?
-在其它大多数语言中,要么只支持声明可变的变量,要么只支持声明不可变的变量( 例如函数式语言 ),前者为编程提供了灵活性,后者为编程提供了安全性,而 Rust 比较野,选择了两者我都要,既要灵活性又要安全性。
+在其它大多数语言中,要么只支持声明可变的变量,要么只支持声明不可变的变量(例如函数式语言),前者为编程提供了灵活性,后者为编程提供了安全性,而 Rust 比较野,选择了两者我都要,既要灵活性又要安全性。
能想要学习 Rust,说明我们的读者都是相当有水平的程序员了,你们应该能理解**一切选择皆是权衡**,那么两者都要的权衡是什么呢?这就是 Rust 开发团队为我们做出的贡献,两者都要意味着 Rust 语言底层代码的实现复杂度大幅提升,因此 Salute to The Rust Team!
@@ -122,7 +122,7 @@ warning: unused variable: `y`
可以看到,两个变量都是只有声明,没有使用,但是编译器却独独给出了 `y` 未被使用的警告,充分说明了 `_` 变量名前缀在这里发挥的作用。
-值得注意的是,这里编译器还很善意的给出了提示( Rust 的编译器非常强大,这里的提示只是小意思 ): 将 `y` 修改 `_y` 即可。这里就不再给出代码,留给大家手动尝试并观察下运行结果。
+值得注意的是,这里编译器还很善意的给出了提示(Rust 的编译器非常强大,这里的提示只是小意思):将 `y` 修改 `_y` 即可。这里就不再给出代码,留给大家手动尝试并观察下运行结果。
更多关于 `_x` 的使用信息,请阅读后面的[模式匹配章节](https://course.rs/basic/match-pattern/all-patterns.html?highlight=_#使用下划线开头忽略未使用的变量)。
diff --git a/src/basic/base-type/index.md b/src/basic/base-type/index.md
index d5c0d86e..94743d8d 100644
--- a/src/basic/base-type/index.md
+++ b/src/basic/base-type/index.md
@@ -1,18 +1,18 @@
# 基本类型
-当一门语言不谈类型时,你得小心,这大概率是动态语言(别拍我,我承认是废话)。但是把类型大张旗鼓的用多个章节去讲的,Rust 是其中之一。
+当一门语言不谈类型时,你得小心,这大概率是动态语言(别拍我,我承认是废话)。但是把类型大张旗鼓的用多个章节去讲的,Rust 是其中之一。
-Rust 每个值都有其确切的数据类型,总的来说可以分为两类:基本类型和复合类型。 基本类型意味着它们往往是一个最小化原子类型,无法解构为其它类型(一般意义上来说),由以下组成:
+Rust 每个值都有其确切的数据类型,总的来说可以分为两类:基本类型和复合类型。 基本类型意味着它们往往是一个最小化原子类型,无法解构为其它类型(一般意义上来说),由以下组成:
-- 数值类型: 有符号整数 (`i8`, `i16`, `i32`, `i64`, `isize`)、 无符号整数 (`u8`, `u16`, `u32`, `u64`, `usize`) 、浮点数 (`f32`, `f64`)、以及有理数、复数
+- 数值类型:有符号整数 (`i8`, `i16`, `i32`, `i64`, `isize`)、 无符号整数 (`u8`, `u16`, `u32`, `u64`, `usize`) 、浮点数 (`f32`, `f64`)、以及有理数、复数
- 字符串:字符串字面量和字符串切片 `&str`
-- 布尔类型: `true`和`false`
-- 字符类型: 表示单个 Unicode 字符,存储为 4 个字节
-- 单元类型: 即 `()` ,其唯一的值也是 `()`
+- 布尔类型:`true` 和 `false`
+- 字符类型:表示单个 Unicode 字符,存储为 4 个字节
+- 单元类型:即 `()` ,其唯一的值也是 `()`
## 类型推导与标注
-与 Python、JavaScript 等动态语言不同,Rust 是一门静态类型语言,也就是编译器必须在编译期知道我们所有变量的类型,但这不意味着你需要为每个变量指定类型,因为 **Rust 编译器很聪明,它可以根据变量的值和上下文中的使用方式来自动推导出变量的类型**,同时编译器也不够聪明,在某些情况下,它无法推导出变量类型,需要手动去给予一个类型标注,关于这一点在 [Rust 语言初印象](https://course.rs/first-try/hello-world.html#rust-语言初印象)中有过展示。
+与 Python、JavaScript 等动态语言不同,Rust 是一门静态类型语言,也就是编译器必须在编译期知道我们所有变量的类型,但这不意味着你需要为每个变量指定类型,因为 **Rust 编译器很聪明,它可以根据变量的值和上下文中的使用方式来自动推导出变量的类型**,同时编译器也不够聪明,在某些情况下,它无法推导出变量类型,需要手动去给予一个类型标注,关于这一点在 [Rust 语言初印象](https://course.rs/first-try/hello-world.html#rust-语言初印象) 中有过展示。
来看段代码:
diff --git a/src/basic/base-type/numbers.md b/src/basic/base-type/numbers.md
index b9ba7175..25d47350 100644
--- a/src/basic/base-type/numbers.md
+++ b/src/basic/base-type/numbers.md
@@ -22,7 +22,7 @@ Rust 使用一个相对传统的语法来创建整数(`1`,`2`,...)和浮
| 128 位 | `i128` | `u128` |
| 视架构而定 | `isize` | `usize` |
-类型定义的形式统一为:`有无符号 + 类型大小(位数)`。**无符号数**表示数字只能取正数和0,而**有符号**则表示数字可以取正数、负数还有0。就像在纸上写数字一样:当要强调符号时,数字前面可以带上正号或负号;然而,当很明显确定数字为正数时,就不需要加上正号了。有符号数字以[补码](https://en.wikipedia.org/wiki/Two%27s_complement)形式存储。
+类型定义的形式统一为:`有无符号 + 类型大小(位数)`。**无符号数**表示数字只能取正数和 0,而**有符号**则表示数字可以取正数、负数还有 0。就像在纸上写数字一样:当要强调符号时,数字前面可以带上正号或负号;然而,当很明显确定数字为正数时,就不需要加上正号了。有符号数字以[补码](https://en.wikipedia.org/wiki/Two%27s_complement)形式存储。
每个有符号类型规定的数字范围是 -(2n - 1) ~ 2n -
1 - 1,其中 `n` 是该定义形式的位长度。因此 `i8` 可存储数字范围是 -(27) ~ 27 - 1,即 -128 ~ 127。无符号类型可以存储的数字范围是 0 ~ 2n - 1,所以 `u8` 能够存储的数字为 0 ~ 28 - 1,即 0 ~ 255。
@@ -112,7 +112,7 @@ fn main() {
}
```
-你可能以为,这段代码没啥问题吧,实际上它会 _panic_(程序崩溃,抛出异常),因为二进制精度问题,导致了 0.1 + 0.2 并不严格等于 0.3,它们可能在小数点 N 位后存在误差。
+你可能以为,这段代码没啥问题吧,实际上它会 _panic_(程序崩溃,抛出异常),因为二进制精度问题,导致了 0.1 + 0.2 并不严格等于 0.3,它们可能在小数点 N 位后存在误差。
那如果非要进行比较呢?可以考虑用这种方式 `(0.1_f64 + 0.2 - 0.3).abs() < 0.00001` ,具体小于多少,取决于你对精度的需求。
@@ -161,7 +161,7 @@ note: run with `RUST_BACKTRACE=1` environment variable to display
#### NaN
-对于数学上未定义的结果,例如对负数取平方根 `-42.1.sqrt()` ,会产生一个特殊的结果:Rust 的浮点数类型使用 `NaN` (not a number)来处理这些情况。
+对于数学上未定义的结果,例如对负数取平方根 `-42.1.sqrt()` ,会产生一个特殊的结果:Rust 的浮点数类型使用 `NaN` (not a number) 来处理这些情况。
**所有跟 `NaN` 交互的操作,都会返回一个 `NaN`**,而且 `NaN` 不能用来比较,下面的代码会崩溃:
@@ -243,7 +243,7 @@ fn main() {
## 位运算
-Rust的位运算基本上和其他语言一样
+Rust 的位运算基本上和其他语言一样
| 运算符 | 说明 |
| ------- | ------------------------------------------------------ |
diff --git a/src/basic/base-type/statement-expression.md b/src/basic/base-type/statement-expression.md
index b13e027b..31acf29e 100644
--- a/src/basic/base-type/statement-expression.md
+++ b/src/basic/base-type/statement-expression.md
@@ -14,7 +14,7 @@ fn add_with_extra(x: i32, y: i32) -> i32 {
-对于 Rust 语言而言,**这种基于语句(statement)和表达式(expression)的方式是非常重要的,你需要能明确的区分这两个概念**, 但是对于很多其它语言而言,这两个往往无需区分。基于表达式是函数式语言的重要特征,**表达式总要返回值**。
+对于 Rust 语言而言,**这种基于语句(statement)和表达式(expression)的方式是非常重要的,你需要能明确的区分这两个概念**,但是对于很多其它语言而言,这两个往往无需区分。基于表达式是函数式语言的重要特征,**表达式总要返回值**。
其实,在此之前,我们已经多次使用过语句和表达式。
diff --git a/src/basic/ownership/borrowing.md b/src/basic/ownership/borrowing.md
index b5a79474..58f5db0d 100644
--- a/src/basic/ownership/borrowing.md
+++ b/src/basic/ownership/borrowing.md
@@ -225,7 +225,7 @@ fn main() {
// 新编译器中,r3作用域在这里结束
```
-在老版本的编译器中(Rust 1.31 前),将会报错,因为 `r1` 和 `r2` 的作用域在花括号 `}` 处结束,那么 `r3` 的借用就会触发 **无法同时借用可变和不可变**的规则。
+在老版本的编译器中(Rust 1.31 前),将会报错,因为 `r1` 和 `r2` 的作用域在花括号 `}` 处结束,那么 `r3` 的借用就会触发 **无法同时借用可变和不可变** 的规则。
但是在新的编译器中,该代码将顺利通过,因为 **引用作用域的结束位置从花括号变成最后一次使用的位置**,因此 `r1` 借用和 `r2` 借用在 `println!` 后,就结束了,此时 `r3` 可以顺利借用到可变引用。
@@ -307,7 +307,7 @@ fn no_dangle() -> String {
总的来说,借用规则如下:
-- 同一时刻,你只能拥有要么一个可变引用, 要么任意多个不可变引用
+- 同一时刻,你只能拥有要么一个可变引用,要么任意多个不可变引用
- 引用必须总是有效的
## 课后练习
diff --git a/src/basic/ownership/ownership.md b/src/basic/ownership/ownership.md
index 990f34be..c5458bf6 100644
--- a/src/basic/ownership/ownership.md
+++ b/src/basic/ownership/ownership.md
@@ -23,17 +23,17 @@ int* foo() {
} // 变量a和c的作用域结束
```
-这段代码虽然可以编译通过,但是其实非常糟糕,变量 `a` 和 `c` 都是局部变量,函数结束后将局部变量 `a` 的地址返回,但局部变量 `a` 存在栈中,在离开作用域后,`a` 所申请的栈上内存都会被系统回收,从而造成了 `悬空指针(Dangling Pointer)` 的问题。这是一个非常典型的内存安全问题,虽然编译可以通过,但是运行的时候会出现错误, 很多编程语言都存在。
+这段代码虽然可以编译通过,但是其实非常糟糕,变量 `a` 和 `c` 都是局部变量,函数结束后将局部变量 `a` 的地址返回,但局部变量 `a` 存在栈中,在离开作用域后,`a` 所申请的栈上内存都会被系统回收,从而造成了 `悬空指针(Dangling Pointer)` 的问题。这是一个非常典型的内存安全问题,虽然编译可以通过,但是运行的时候会出现错误,很多编程语言都存在。
再来看变量 `c`,`c` 的值是常量字符串,存储于常量区,可能这个函数我们只调用了一次,也可能我们不再会使用这个字符串,但 `"xyz"` 只有当整个程序结束后系统才能回收这片内存。
-所以内存安全问题,一直都是程序员非常头疼的问题,好在, 在 Rust 中这些问题即将成为历史,因为 Rust 在编译的时候就可以帮助我们发现内存不安全的问题,那 Rust 如何做到这一点呢?
+所以内存安全问题,一直都是程序员非常头疼的问题,好在,在 Rust 中这些问题即将成为历史,因为 Rust 在编译的时候就可以帮助我们发现内存不安全的问题,那 Rust 如何做到这一点呢?
在正式进入主题前,先来一个预热知识。
## 栈(Stack)与堆(Heap)
-栈和堆是编程语言最核心的数据结构,但是在很多语言中,你并不需要深入了解栈与堆。 但对于 Rust 这样的系统编程语言,值是位于栈上还是堆上非常重要, 因为这会影响程序的行为和性能。
+栈和堆是编程语言最核心的数据结构,但是在很多语言中,你并不需要深入了解栈与堆。 但对于 Rust 这样的系统编程语言,值是位于栈上还是堆上非常重要,因为这会影响程序的行为和性能。
栈和堆的核心目标就是为程序在运行时提供可供使用的内存空间。
@@ -49,11 +49,11 @@ int* foo() {
与栈不同,对于大小未知或者可能变化的数据,我们需要将它存储在堆上。
-当向堆上放入数据时,需要请求一定大小的内存空间。操作系统在堆的某处找到一块足够大的空位,把它标记为已使用,并返回一个表示该位置地址的**指针**, 该过程被称为**在堆上分配内存**,有时简称为 “分配”(allocating)。
+当向堆上放入数据时,需要请求一定大小的内存空间。操作系统在堆的某处找到一块足够大的空位,把它标记为已使用,并返回一个表示该位置地址的**指针**,该过程被称为**在堆上分配内存**,有时简称为 “分配”(allocating)。
接着,该指针会被推入**栈**中,因为指针的大小是已知且固定的,在后续使用过程中,你将通过栈中的**指针**,来获取数据在堆上的实际内存位置,进而访问该数据。
-由上可知,堆是一种缺乏组织的数据结构。想象一下去餐馆就座吃饭: 进入餐馆,告知服务员有几个人,然后服务员找到一个够大的空桌子(堆上分配的内存空间)并领你们过去。如果有人来迟了,他们也可以通过桌号(栈上的指针)来找到你们坐在哪。
+由上可知,堆是一种缺乏组织的数据结构。想象一下去餐馆就座吃饭:进入餐馆,告知服务员有几个人,然后服务员找到一个够大的空桌子(堆上分配的内存空间)并领你们过去。如果有人来迟了,他们也可以通过桌号(栈上的指针)来找到你们坐在哪。
#### 性能区别
@@ -74,12 +74,12 @@ int* foo() {
> 1. Rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者
> 2. 一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者
-> 3. 当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
+> 3. 当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
#### 变量作用域
-作用域是一个变量在程序中有效的范围, 假如有这样一个变量:
+作用域是一个变量在程序中有效的范围,假如有这样一个变量:
```rust
let s = "hello";
@@ -106,7 +106,7 @@ let s = "hello";
- **字符串字面值是不可变的**,因为被硬编码到程序代码中
- 并非所有字符串的值都能在编写代码时得知
-例如,字符串是需要程序运行时,通过用户动态输入然后存储在内存中的,这种情况,字符串字面值就完全无用武之地。 为此,Rust 为我们提供动态字符串类型: `String`, 该类型被分配到堆上,因此可以动态伸缩,也就能存储在编译时大小未知的文本。
+例如,字符串是需要程序运行时,通过用户动态输入然后存储在内存中的,这种情况,字符串字面值就完全无用武之地。 为此,Rust 为我们提供动态字符串类型: `String`,该类型被分配到堆上,因此可以动态伸缩,也就能存储在编译时大小未知的文本。
可以使用下面的方法基于字符串字面量来创建 `String` 类型:
@@ -139,7 +139,7 @@ let y = x;
这段代码并没有发生所有权的转移,原因很简单: 代码首先将 `5` 绑定到变量 `x`,接着**拷贝** `x` 的值赋给 `y`,最终 `x` 和 `y` 都等于 `5`,因为整数是 Rust 基本数据类型,是固定大小的简单值,因此这两个值都是通过**自动拷贝**的方式来赋值的,都被存在栈中,完全无需在堆上分配内存。
-整个过程中的赋值都是通过值拷贝的方式完成(发生在栈中),因此并不需要所有权转移。
+整个过程中的赋值都是通过值拷贝的方式完成(发生在栈中),因此并不需要所有权转移。
> 可能有同学会有疑问:这种拷贝不消耗性能吗?实际上,这种栈上的数据足够简单,而且拷贝非常非常快,只需要复制一个整数大小(`i32`,4 个字节)的内存即可,因此在这种情况下,拷贝的速度远比在堆上创建内存来得快的多。实际上,上一章我们讲到的 Rust 基本类型都是通过自动拷贝的方式来赋值的,就像上面代码一样。
@@ -204,7 +204,7 @@ For more information about this error, try `rustc --explain E0382`.
> 1. Rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者
> 2. 一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者
-> 3. 当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
+> 3. 当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
如果你在其他语言中听说过术语 **浅拷贝(shallow copy)** 和 **深拷贝(deep copy)**,那么拷贝指针、长度和容量而不拷贝数据听起来就像浅拷贝,但是又因为 Rust 同时使第一个变量 `s1` 无效了,因此这个操作被称为 **移动(move)**,而不是浅拷贝。上面的例子可以解读为 `s1` 被**移动**到了 `s2` 中。那么具体发生了什么,用一张图简单说明:
@@ -243,7 +243,7 @@ println!("s1 = {}, s2 = {}", s1, s2);
这段代码能够正常运行,说明 `s2` 确实完整的复制了 `s1` 的数据。
-如果代码性能无关紧要,例如初始化程序时或者在某段时间只会执行寥寥数次时,你可以使用 `clone` 来简化编程。但是对于执行较为频繁的代码(热点路径),使用 `clone` 会极大的降低程序性能,需要小心使用!
+如果代码性能无关紧要,例如初始化程序时或者在某段时间只会执行寥寥数次时,你可以使用 `clone` 来简化编程。但是对于执行较为频繁的代码(热点路径),使用 `clone` 会极大的降低程序性能,需要小心使用!
#### 拷贝(浅拷贝)
@@ -271,7 +271,7 @@ Rust 有一个叫做 `Copy` 的特征,可以用在类似整型这样在栈中
- 所有浮点数类型,比如 `f64`
- 字符类型,`char`
- 元组,当且仅当其包含的类型也都是 `Copy` 的时候。比如,`(i32, i32)` 是 `Copy` 的,但 `(i32, String)` 就不是
-- 不可变引用 `&T` ,例如[转移所有权](#转移所有权)中的最后一个例子,**但是注意: 可变引用 `&mut T` 是不可以 Copy的**
+- 不可变引用 `&T` ,例如[转移所有权](#转移所有权)中的最后一个例子,**但是注意:可变引用 `&mut T` 是不可以 Copy的**
## 函数传值与返回
diff --git a/src/basic/variable.md b/src/basic/variable.md
index a6e5470a..e815af09 100644
--- a/src/basic/variable.md
+++ b/src/basic/variable.md
@@ -4,7 +4,7 @@
## 为何要手动设置变量的可变性?
-在其它大多数语言中,要么只支持声明可变的变量,要么只支持声明不可变的变量( 例如函数式语言 ),前者为编程提供了灵活性,后者为编程提供了安全性,而 Rust 比较野,选择了两者我都要,既要灵活性又要安全性。
+在其它大多数语言中,要么只支持声明可变的变量,要么只支持声明不可变的变量(例如函数式语言),前者为编程提供了灵活性,后者为编程提供了安全性,而 Rust 比较野,选择了两者我都要,既要灵活性又要安全性。
能想要学习 Rust,说明我们的读者都是相当有水平的程序员了,你们应该能理解**一切选择皆是权衡**,那么两者都要的权衡是什么呢?这就是 Rust 开发团队为我们做出的贡献,两者都要意味着 Rust 语言底层代码的实现复杂度大幅提升,因此 Salute to The Rust Team!
@@ -122,7 +122,7 @@ warning: unused variable: `y`
可以看到,两个变量都是只有声明,没有使用,但是编译器却独独给出了 `y` 未被使用的警告,充分说明了 `_` 变量名前缀在这里发挥的作用。
-值得注意的是,这里编译器还很善意的给出了提示( Rust 的编译器非常强大,这里的提示只是小意思 ): 将 `y` 修改 `_y` 即可。这里就不再给出代码,留给大家手动尝试并观察下运行结果。
+值得注意的是,这里编译器还很善意的给出了提示(Rust 的编译器非常强大,这里的提示只是小意思):将 `y` 修改 `_y` 即可。这里就不再给出代码,留给大家手动尝试并观察下运行结果。
更多关于 `_x` 的使用信息,请阅读后面的[模式匹配章节](https://course.rs/basic/match-pattern/all-patterns.html?highlight=_#使用下划线开头忽略未使用的变量)。